Results
BioML-Bench
BioML-Bench is a benchmark of 24 end-to-end biomedical ML tasks spanning biomedical imaging (4), drug discovery (9), protein engineering (6), and single-cell omics (5). Each task provides a natural-language description and training data; submissions are graded against hidden test labels by an external evaluator. We report leaderboard percentile relative to public human submissions, above-median rate, and medal rate. AutoScientists achieves a mean leaderboard percentile of 74.40% (SE 6.20) vs. 66.07% for autoresearch (+8.33 points), with the largest gain in drug discovery (64.52% vs. 46.16% for Biomni). Error bars are standard errors of the mean.
GPT Training Optimization
AutoScientists is applied to the GPT nanochat training optimization task.
Each experiment is a single 5-minute training run on one H100 GPU, scored by
validation bits-per-byte (val_bpb, lower is better).
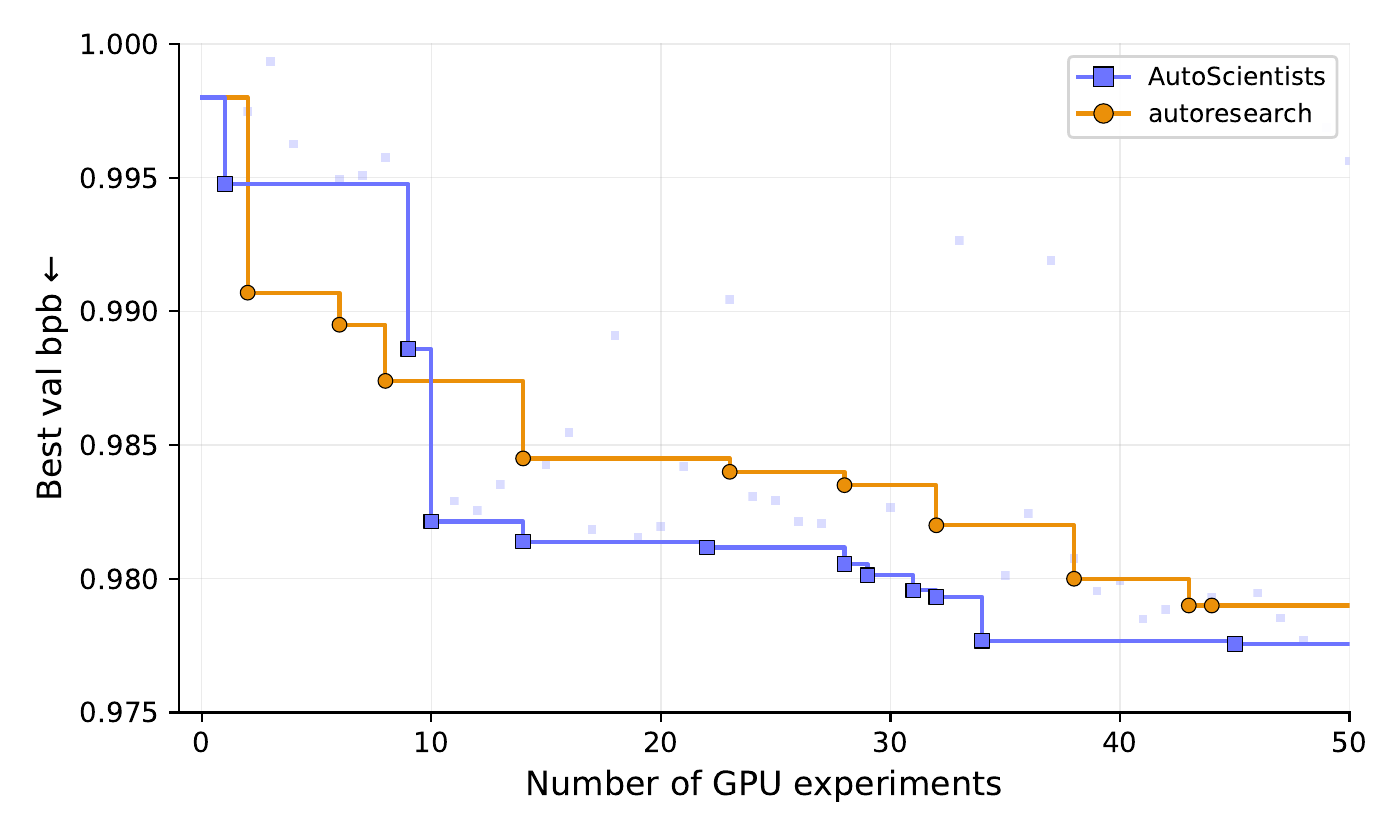
From the autoresearch baseline (val_bpb = 0.998):
AutoScientists reaches val_bpb ≈ 0.978 in 34 experiments vs.
65 for autoresearch — a 1.9× speedup at matched loss.
Agents formed three parallel teams (architecture, schedule, optimizer) while the
single-agent loop advances one axis per experiment.
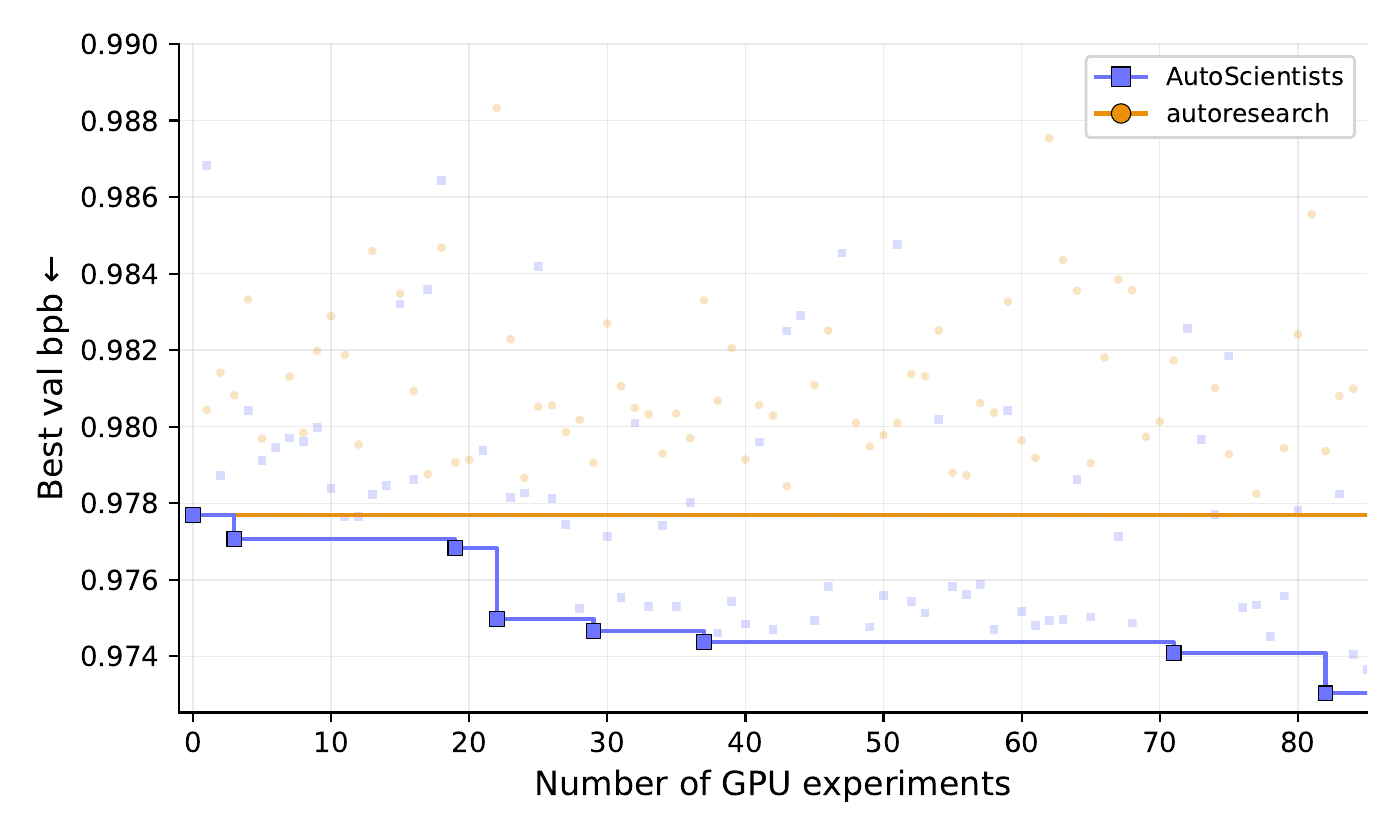
From the AutoScientists champion (val_bpb = 0.9777):
AutoScientists accepts 7 improvements reaching 0.9730 across
heterogeneous directions (normalization order, matrix initialization, learning-rate
fraction, softcap, compile autotuning). Autoresearch finds none in 100 experiments.
ProteinGym
AutoScientists starts from Kermut — a Gaussian-process method and the best-performing supervised baseline — and modifies it on a single development assay (ACE2–Spike binding) with no access to the full benchmark. The discovered recipe is a three-GP ensemble combining Kermut’s structure-kernel with expanded zero-shot features, greedy diversity-based feature selection, and quantile-warped targets. On the development assay, mean Spearman ρ improves from 0.747 to 0.840 (+12.5% relative). The frozen recipe transfers without modification across all 217 DMS assays, improving the official average Spearman ρ from 0.657 to 0.700 (+6.5% relative) across all three cross-validation schemes. Values are mean (SE) from the official ProteinGym aggregation pipeline.